Enda otsingumootor ehk kuidas otsida infot staatiliselt veebisaidilt (Apache Solr ja Nutch)
08.01.2018Eelmises artiklis oli natuke juttu staatilise veebisaidi eelistest. Nii nagu staatilist veebisaiti tehes, võib koostada ka dokumendikogu, kasutades markdown süntaksit.
Kuidas aga korraldada otsing, kui soovime dokumente hoida vaid sisevõrgus? Keegi ei keela enda otsingumootori püstipanekut. Toon siin lihtsa näite, kuidas seda teha Apache Solr ja Apache Nutch abil. Siintoodud juhend on Linux keskkonnas, kuid see töötab ka näiteks WSL keskkonnas.
Internetis on üsna hea lihtne juhend: https://factorpad.com/tech/solr/tutorial/solr-web-crawl.html. Ainuke häda on see, et veebisaidi sisu allalaadides -recursive võtmega kipub ilmuma veateade "[Fatal Error] :1:1: Content is not allowed in prolog." Selleks, et sellest üle saada, kasutame Apache Nutch-i.
Kuna lihtsasti mõistetavat ja töötavat õpetust oli raske leida, panen siis selle nüüd kirja.
tiit@tiit-Virtual-Machine:~$ cd
tiit@tiit-Virtual-Machine:~$ mkdir solr
tiit@tiit-Virtual-Machine:~$ cd solr
tiit@tiit-Virtual-Machine:~/solr$ wget http://www-us.apache.org/dist/lucene/solr/7.2.0/solr-7.2.0.tgz
tiit@tiit-Virtual-Machine:~/solr$ tar xf solr-7.2.0.tgz
tiit@tiit-Virtual-Machine:~/solr$ cd solr-7.2.0/
tiit@tiit-Virtual-Machine:~/solr/solr-7.2.0$ bin/solr start
tiit@tiit-Virtual-Machine:~/solr/solr-7.2.0$ bin/solr create_core -c infokiir
WARNING: Using _default configset. Data driven schema functionality is enabled by default, which is
NOT RECOMMENDED for production use.
To turn it off:
curl http://localhost:8983/solr/infokiir/config -d '{"set-user-property": {"update.autoCreateFields":"false"}}'
Created new core 'infokiir'
tiit@tiit-Virtual-Machine:~/solr/solr-7.2.0$
Veendume ka, et meil oleks java installeeritud:
tiit@tiit-Virtual-Machine:~/solr/solr-7.2.0$ java -version
openjdk version "1.8.0_151"
OpenJDK Runtime Environment (build 1.8.0_151-8u151-b12-0ubuntu0.16.04.2-b12)
OpenJDK 64-Bit Server VM (build 25.151-b12, mixed mode)
Juhul, kui JAVA_HOME ei ole väärtustatud, siis teen seda käsklusega:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Edasi:
tiit@tiit-Virtual-Machine:~/solr/solr-7.2.0$ cd
tiit@tiit-Virtual-Machine:~$ mkdir nutch
tiit@tiit-Virtual-Machine:~$ cd nutch/
tiit@tiit-Virtual-Machine:~/nutch$ wget http://www-eu.apache.org/dist/nutch/1.14/apache-nutch-1.14-bin.tar.gz
--2018-01-08 14:04:20-- http://www-eu.apache.org/dist/nutch/1.14/apache-nutch-1.14-bin.tar.gz
Lahendan www-eu.apache.org (www-eu.apache.org)... 195.154.151.36, 2001:bc8:2142:300::
Loon ühendust serveriga www-eu.apache.org (www-eu.apache.org)|195.154.151.36|:80... ühendus loodud.
HTTP päring saadetud, ootan vastust... 200 OK
Pikkus: 249107211 (238M) [application/x-gzip]
Salvestan: `apache-nutch-1.14-bin.tar.gz'
apache-nutch-1.14-bin.tar.gz 100%[=============================================================================================>] 237,57M 5,30MB/s in 48s
2018-01-08 14:05:09 (4,93 MB/s) - `apache-nutch-1.14-bin.tar.gz' salvestatud [249107211/249107211]
tiit@tiit-Virtual-Machine:~/nutch$ tar xf apache-nutch-1.14-bin.tar.gz
tiit@tiit-Virtual-Machine:~/nutch$ cd apache-nutch-1.14/
Proovin, kas crawl käivitub:
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$ bin/crawl
Usage: crawl [-i|--index] [-D "key=value"] [-w|--wait] [-s <Seed Dir>] <Crawl Dir> <Num Rounds>
-i|--index Indexes crawl results into a configured indexer
-D A Java property to pass to Nutch calls
-w|--wait NUMBER[SUFFIX] Time to wait before generating a new segment when no URLs
are scheduled for fetching. Suffix can be: s for second,
m for minute, h for hour and d for day. If no suffix is
specified second is used by default.
-s Seed Dir Path to seeds file(s)
Crawl Dir Directory where the crawl/link/segments dirs are saved
Num Rounds The number of rounds to run this crawl for
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$
Edasi seadistame mõned parameetrid:
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$ nano conf/nutch-site.xml
Kopeerin "configuration" tag-de vahele (sisu laenatud veebisaidilt http://opensourceconnections.com/blog/2014/05/24/crawling-with-nutch/):
<property>
<name>http.agent.name</name>
<value>MyBot</value>
<description>MUST NOT be empty. The advertised version will have Nutch appended.</description>
</property>
<property>
<name>http.robots.agents</name>
<value>MyBot,*</value>
<description>The agent strings we'll look for in robots.txt files,
comma-separated, in decreasing order of precedence. You should
put the value of http.agent.name as the first agent name, and keep the
default * at the end of the list. E.g.: BlurflDev,Blurfl,*. If you don't, your logfile will be full of warnings.
</description>
</property>
<property>
<name>fetcher.store.content</name>
<value>true</value>
<description>If true, fetcher will store content. Helpful on the getting-started stage, as you can recover failed steps, but may cause performance problems on larger crawls.</description>
</property>
<property>
<name>fetcher.max.crawl.delay</name>
<value>-1</value>
<description>
If the Crawl-Delay in robots.txt is set to greater than this value (in
seconds) then the fetcher will skip this page, generating an error report. If set to -1 the fetcher will never skip such pages and will wait the amount of time retrieved from robots.txt Crawl-Delay, however long that might be.
</description>
</property>
<!-- Applicable plugins-->
<property>
<name>plugin.includes</name>
<value>protocol-http|urlfilter-regex|parse-(html|tika|metatags)|index-(basic|anchor|metadata)|query-(basic|site|url)|response-(json|xml)|summary-basic|scoring-opic|indexer-solr|urlnormalizer-(pass|regex|basic)</value>
<description> At the very least, I needed to add the parse-html, urlfilter-regex, and the indexer-solr.
</description>
</property>
```
```bash
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$ nano urls/seed.text
Lisan siia rea:
http://www.infokiir.ee
Kommenteerin välja viimase rea ja lisan:
#+.
+^https?://([a-z0-9-]+\.)*www\.infokiir\.ee/
See on vajalik selleks, et me püsiks www.infokiir.ee veebisaidil ega hakkaks alla laadima väliseid viidatud veebisaite.
Veebisaidi sisu allalaadimine käib kahes etapis. Kõigepealt käivitan:
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$ bin/crawl -s urls crawl/ 2
Seejärel:
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$ bin/nutch solrindex http://localhost:8983/solr/infokiir crawl/crawldb/ crawl/segments/*
Segment dir is complete: crawl/segments/20180108144502.
Segment dir is complete: crawl/segments/20180108144521.
Indexer: starting at 2018-01-08 14:48:13
Indexer: deleting gone documents: false
Indexer: URL filtering: false
Indexer: URL normalizing: false
Active IndexWriters :
SOLRIndexWriter
solr.server.url : URL of the SOLR instance
solr.zookeeper.hosts : URL of the Zookeeper quorum
solr.commit.size : buffer size when sending to SOLR (default 1000)
solr.mapping.file : name of the mapping file for fields (default solrindex-mapping.xml)
solr.auth : use authentication (default false)
solr.auth.username : username for authentication
solr.auth.password : password for authentication
Indexing 6/6 documents
Deleting 0 documents
Indexer: number of documents indexed, deleted, or skipped:
Indexer: 6 indexed (add/update)
Indexer: finished at 2018-01-08 14:48:16, elapsed: 00:00:02
tiit@tiit-Virtual-Machine:~/nutch/apache-nutch-1.14$
Nüüd vaatan tulemust:
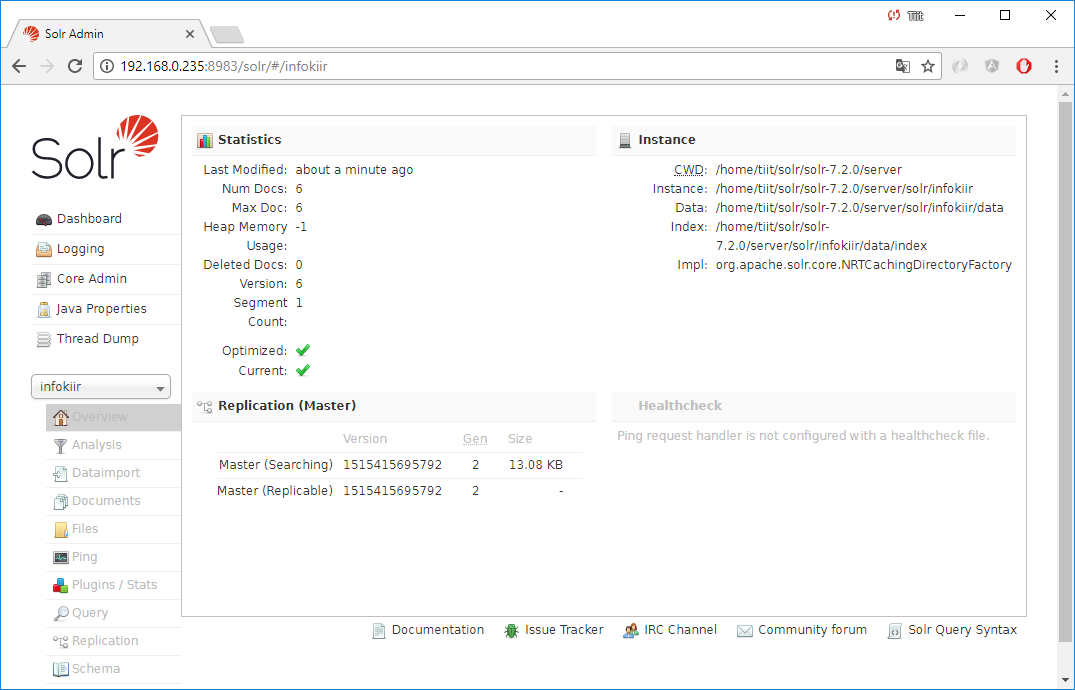
Otsing:
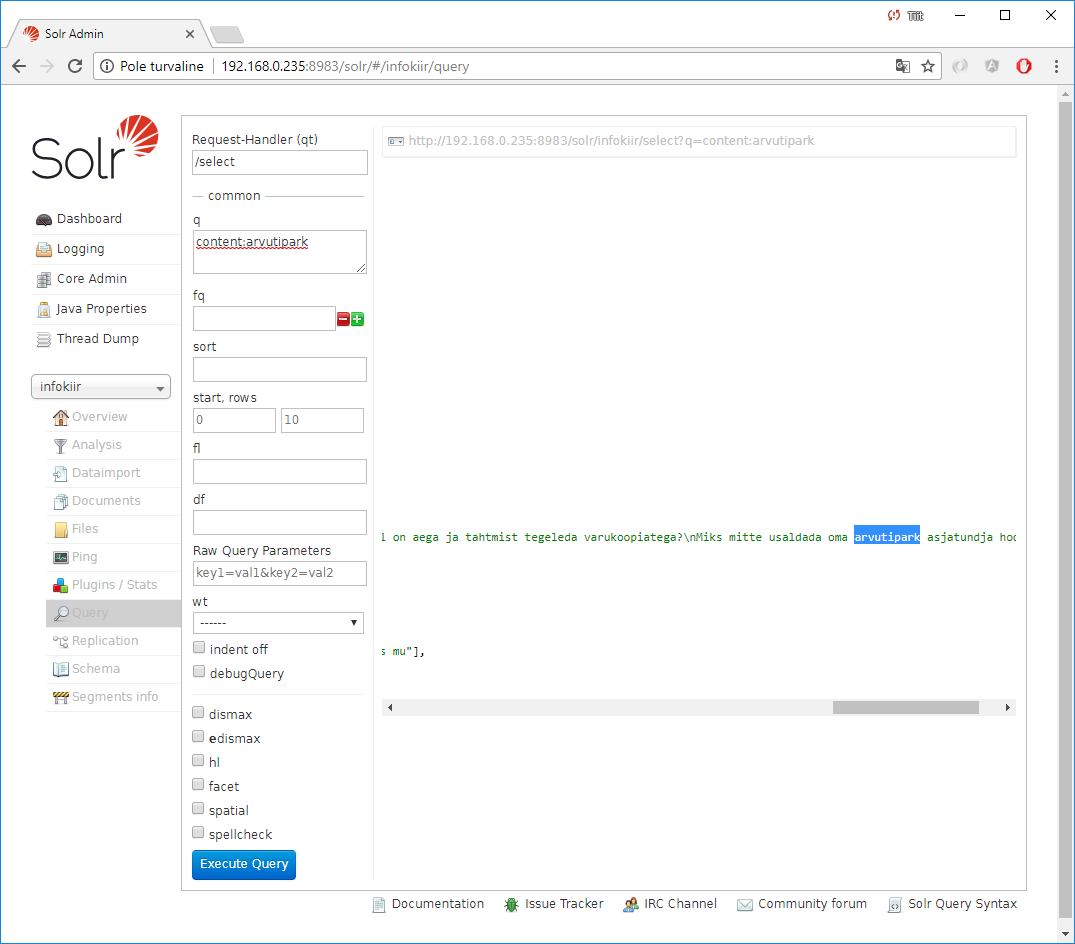
Linke:
https://et.wikipedia.org/wiki/Markdown
https://lucene.apache.org/solr/
https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux
https://factorpad.com/tech/solr/tutorial/solr-web-crawl.html
http://opensourceconnections.com/blog/2014/05/24/crawling-with-nutch/
https://lobster1234.github.io/2017/08/14/search-with-nutch-mongodb-solr/